Давайте для примера проиндексируем документ ниже:
PUT example4/person/1
{
"id": 1,
"name": "user1",
"age": "55",
"gender": "M",
"email": "[email protected]",
"last_modified_date": "2017-02-15"
}
Документ, который мы только что проиндексировали, уникально идентифицируется индексом (example4), типом (person) и идентификатором (1). Вы можете указать свой идентификатор, как в данном случае или позволить Elasticsearch выбрать его для вас. Если вы хотите указать идентификатор, вы должны использовать PUTметод. Если вы используете POST, документу автоматически присваивается уникальный идентификатор. Ответ на предыдущую команду:
{
"_index": "example4",
"_type": "person",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
Операция индекса создает документ, если документ не существует. Если документ с тем же идентификатором уже существует, содержимое документа заменяется, а версия увеличивается. Вы увидите ответ, как показано ниже:
{
"_index": "example4",
"_type": "person",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
Как видно в ответе result: updated, а created: false. Так же Elasticsearc можно указать только создать документ, а не заменять если такой уже есть, с помощью параметра opt_type=create:
PUT example4/person/1?op_type=create
{
"id": 1,
"name": "user1",
"age": "55",
"gender": "M",
"email": "[email protected]",
"last_modified_date": "2017-02-15"
}
Если документ с таким же идентификатором уже существует, операция отклоняется возвращая в ответ ошибку. Ответ:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[person][1]: version conflict, document already exists..",
"index_uuid": "9rcbu7LZR42te04D_G9r-g",
"shard": "0",
"index": "example4"
}
],
"type": "version_conflict_engine_exception",
"reason": "[person][1]: version conflict, document already exists...",
"index_uuid": "9rcbu7LZR42te04D_G9r-g",
"shard": "0",
"index": "example4"
},
"status": 409
}
Сам ответ имеет код HTTP 409 Conflict.
Ошибки индексирования
Во время индексации могут возникать различные ошибки. В этом разделе мы перечислим наиболее распространенные ошибки и способы их обработки.
Ошибки узла/осколков
Ошибки узла/осколков могут возникать, если узел недоступен или осколок не назначается узлу. В ответе на запрос содержится раздел про осколки, который сообщает нам количество осколков, на которых операция успешна. Несмотря на то, что операция не удалась на всех осколках, Elasticsearch ответит частичными результатами. Например, если вы выполняете запрос к индексу с двумя осколками и один из осколков недоступен, ответ запроса возвращается только от одного осколка. Важно следить за количеством осколков, дабы знать как у нас дела с осколками и системой в целом.
Давай добавим в индекс новую персону:
PUT example4/person/2
{
"id": 2,
"name": "user2",
"age": "55",
"gender": "M",
"email": "[email protected]",
"last_modified_date": "2017-02-18"
}
Ответ:
{
"_index": "example4",
"_type": "person",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
Обратите внимание на полу _shards, где total — количество осколков всего; successful — количество осколков где операция прошла успешно; failed — количество осколков где операция вызвала ошибку. Как видно из ответа всего у нас 2 осколка и только на одном операция прошла успешно. В данном примере наш кластер имеет только один узел. Когда индекс создается, по умолчанию он имеет кроме основного осколка, так же реплику этого осколка. Первичный осколок и реплика не могут находиться на одном узле. Поскольку кластер имеет только один узел, осколок реплики не может быть назначен узлу в кластере, а операция индексирования успешна только на первичной осколке.
Ошибки сериализации / сопоставления
Такие ошибки возникают из-за проблем с сериализацией JSON или если вы пытаетесь проиндексировать поле имеющее целый тип засунув в него строку. Например, есть поле age имеющее целый тип, а мы пытаемся записать туда сроку «one», то мы получим ошибку:
PUT example4/person/3
{
"id": 3,
"name": "user3",
"age": "one",
"gender": "M",
"email": "[email protected]",
"last_modified_date": "2017-02-18"
}
Ответ на предыдущий запрос:
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse [age]"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse [age]",
"caused_by": {
"type": "number_format_exception",
"reason": "For input string: \"one\""
}
},
"status": 400
}
Ошибка отклонения пула потоков
У Elasticsearch есть пул потоков для индекса, поиска, обновления и т. д. Если пул потоков для индексации заполнен, Elasticsearch отклонит операцию индексирования. Если вы иногда получаете эту ошибку, вы можете добавить логику приложения, чтобы повторить операцию индекса. Если вы часто получаете эту ошибку, вам следует подумать о том, чтобы улучшить оборудование или увеличить размер пула потоков.
Размер пула потоков основан на количестве процессоров ЦПУ, доступных в узле. Elasticsearch не рекомендует изменять размер пула потоков по умолчанию, если вы не знаете, что делаете.
Управление индексом
Elasticsearch автоматически создает индекс с настройками по умолчанию и использует динамическое сопоставление для определения соответствия. В предыдущем разделе мы добавили документ в индекс example4. Давайте рассмотрим настройки по умолчанию:
GET example4/_settings
Вы увидите ответ:
{
"example4": {
"settings": {
"index": {
"creation_date": "1493529955647",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "gvScXYjKQVmS6HsYub_Rbg",
"version": {
"created": "5010299"
},
"provided_name": "example4"
}
}
}
}
Вы можете видеть из предыдущего ответа, что индекс был создан с настройками по умолчанию для 5 осколков и 1 реплики, что означает 5 первичных осколков и 5 реплик. Если вам нужно изменить настройки по умолчанию, вам нужно удалить существующий индекс и воссоздать индекс. Вы можете удалить chapter4 индекс, как показано ниже:
DELETE example4
Обратите внимание, что метод HTTP DELETE. Эта единственная команда удаляет индекс, который нельзя отменить. Перед запуском команды delete дважды проверьте имя индекса.
Давайте воссоздаем example4 индекс с 3 осколками и 1 репликами:
PUT example4
{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "1"
}
}
}
Теперь давайте проверим настройки индекса:
GET example4/_settings
Вы увидите ответ следующим образом:
{
"example4": {
"settings": {
"index": {
"creation_date": "1493530055030",
"number_of_shards": "3",
"number_of_replicas": "1",
"uuid": "1eBr7XoMTgyzryJRl4wG8g",
"version": {
"created": "5010299"
},
"provided_name": "example4"
}
}
}
}
После создания индекса количество осколков в индексе не может быть изменено. Если вы хотите увеличить или уменьшить количество осколков, вам нужно создать новый индекс с новыми настройками и переиндексировать данные. Начиная Elasticearch 5.0, вы можете использовать reindex API для воссоздания индекса с различными конфигурациями индексов. Мы обсудим переиндексацию подробно в 5 уроке.
В отличие от количества осколков количество реплик может быть увеличено или уменьшено «на лету» следующим образом:
PUT example4/_settings
{
"index": {
"number_of_replicas": 2
}
}
Вы должны увидеть подтвержденный ответ:
{"acknowledged":true}
Как показано в предыдущем ответе, Elasticsearch принял запрос и начнет работу по репликации осколков в фоновом режиме. Мы создали индекс с необходимой конфигурацией осколков. Далее, давайте установим сопоставления для example4 индекса, product введите, как показано здесь:
PUT example4/_mapping/product
{
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"gender": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"last_modified_date": {
"type": "date"
}
}
}
Мы также можем установить и settings и mappings при создании индекса, как показано ниже:
PUT /example4
{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "1"
}
},
"mappings": {
"product": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"gender": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"last_modified_date": {
"type": "date"
}
}
}
}
}
Теперь мы можем индексировать документы без сюрпризов.
Что происходит, когда вы индексируете документ?
В этом разделе мы обсудим, что происходит внутри, когда вы индексируете документ. Индекс Elasticsearch — это не что иное, как сборник осколков. Каждый осколок, как мы обсуждали ранее, является индексом Lucene. Чтобы иметь возможность искать документы, поля в документах анализируются и сохраняются в инвертированном индексе. В отличие от баз данных SQL, Elasticsearch — это поисковая система в режиме почти реального времени, то есть индексы, которые вы указали, доступны только после небольшой задержки. Значение по умолчанию — 1sec. В конце этого раздела будет понятно, почему существует задержка и как мы можем контролировать задержку.
Во-первых, давайте воссоздаем example4 индекс с 2 осколками и 1 репликой:
DELETE example4
PUT example4
{
"settings": {
"index": {
"number_of_shards": "2",
"number_of_replicas": "1"
}
}
}
Давайте проиндексируем документ в example4 только что созданный индекс:
PUT example4/person/2
{
"id": 2,
"name": "user2",
"age": "55",
"gender": "M",
"email": "[email protected]",
"last_modified_date": "2017-02-18"
}
Поскольку индекс может иметь еще один осколок, Elasticsearch сначала определяет осколок, к которому принадлежит документ, используя формулу hash(document_id) % number_of_shards. При запросу документа по его id используется эта же формула для определения осколка и получения документа.
Так же, как индекс Elasticsearch состоит из нескольких осколков, осколок (индекс Lucene) состоит из нескольких сегментов (s1, s2, s3), как показано ниже. Следующая диаграмма представляет внутренности осколка:
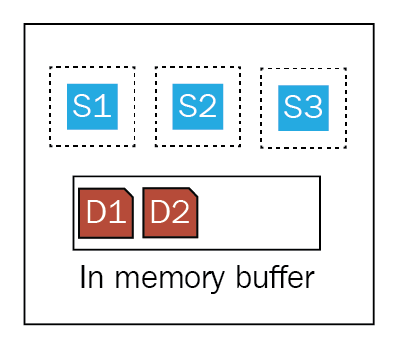
Когда вы индексируете документ в индекс Lucene (осколок), документ сначала записывается в буфер в памяти. Процесс, известный как refresh просыпающийся по расписанию и считывающий документы из буфера в памяти и создающий новый segment. На предыдущей диаграмме при следующем обновлении индекса Lucene создается новый S4 сегмент, содержащий документы D1 и D2.
Каждый сегмент Lucene является независимым индексом, по которому можно искать. По мере добавления новых документов процесс обновления считывает документы из буфера в памяти и создает новые сегменты. Сегмент содержит инвертированный индекс и другую информацию, необходимую для поиска документов. Когда новый сегмент при создании записывается в кэш файловой системы и фиксируется на физическом диске при выполнении определенных условий.
Кэш файловой системы — это системная память, в которой кешируется файл, считанный с физического диска. Следующая операция чтения считывает файл непосредственно из памяти. Кэш файловой системы — это кеш между процессами и физическим диском. Любые записи в файл записываются в кеш, а не на физический диск. Через определенные промежутки времени данные в кеше файловой системы записываются на диск. Таким образом, операционная система оптимизирует стоимость чтения и записи физического диска.
По умолчанию интервал обновления является 1 секунда. Если вам нужен документ для поиска сразу после индекса, вы можете установить refresh=true, как показано ниже:
PUT example4/person/3?refresh=true
{
"id": 3,
"name": "User3",
"age": "55",
"gender": "M",
"email": "[email protected]",
"last_modified_date": "2017-02-15"
}
Предыдущая команда добавить документ в индекс и запустить механизм refresh благодаря чему документ будет доступен для поиска после выполнения операции. Вы также можете вручную обновить весь индекс example4, как показано ниже:
POST example4/_refresh
Вы можете обновить все индексы следующим образом:
POST /_refresh
Refresh — дорогостоящая операция, и в зависимости от того, нужен ли вам поиск в режиме реального времени, вы можете увеличить или уменьшить интервал обновления. Если ваши данные не обязательно должны быть доступны для поиска сразу после индекса, вам следует подумать об увеличении интервала обновления. Например, давай те поставим интервал обновления в 30 секунд. После чего данные для поиска станут доступны только после 30 секунд:
PUT example4/_settings
{
"index": {
"refresh_interval": "30s"
}
}
Во время массовой индексации вы можете временно отключить обновление, чтобы увеличить производительность индексации. Обновление можно отключить, установив refresh_interval в -1. После того, как индексирование завершено, вы можете вернуть refresh_interval назад, как было раньше.